
Star Wars: A Social Network Analysis
WORK-IN-PROGRESS!
This post is a beginners guide on how to apply techniques from social network analysis (SNA) using Python, NetworkX, and Gephi, using Star Wars scripts. It’s derived from a talk I gave at PyConIE 2017 the slide of which can be found here and there is also a recording available on the Python Ireland YouTube channel:
Collect the Scripts
One of the best online resources for finding movie scripts is The Internet Movie Script Database (IMSDB). A quick search for ‘Star Wars’ returns the seven main scripts1.
There are many different ways to collect the scripts, in my case I decided to use the Python package Scrapy:
Scrapy is an application framework for crawling web sites and extracting structured data which can be used for a wide range of useful applications, like data mining, information processing or historical archival.
For the simple purpose of collecting seven scripts, I’m definitely not utilising the full capabilities of Scrapy. However, it has great documentation and as a result, is very quick to implement and extend. The code below is just an adaption of the sample spider project they walk through on their tutorial page.
To collect only the script text from each page, I first needed to inspect the tags used within the site’s HTML. Something that can be easily done if you’re using the web browser Chrome, which just requires you to right-click on the page you’re interested in and selecting Inspect from the resulting menu.
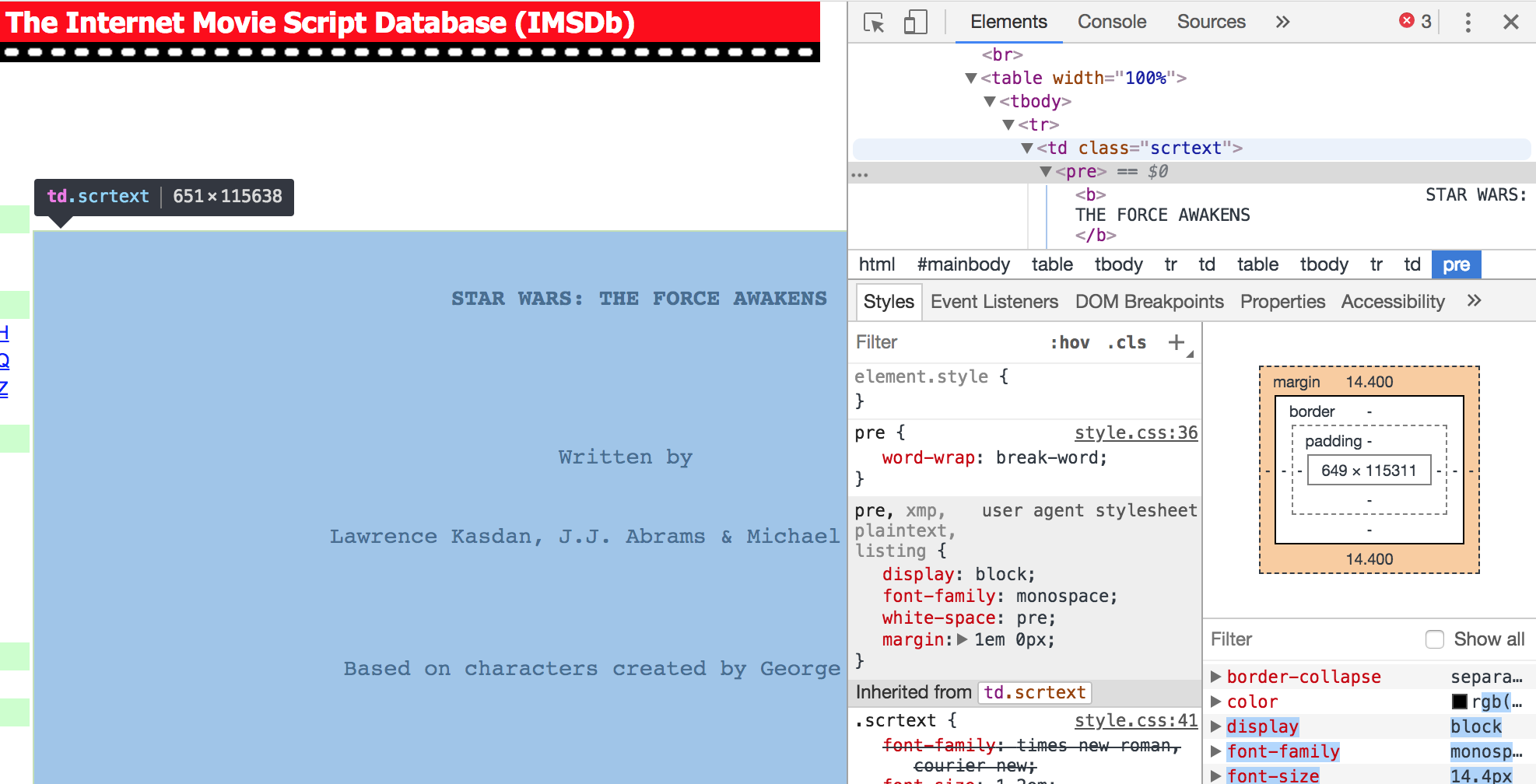
As we can see from the figure above, script text is contained within the HTML tag td class="scrtext" which in turn is nested within the table and body tags2. Using this information, I can then define the following:
response.css('body table td.scrtext')
This means return the text contained between <body><table><td class="scrtext"> tags of the page. For further information on how I arrived at this, check out CSS Selectors.
The code in it’s entirety is as follows:
import scrapy # Import scrapy library.
class ScriptSpider(scrapy.Spider):
name = "scripts" # Name of spider.
allowed_domains = "imsdb.com"
start_urls = [
'http://www.imsdb.com/scripts/Star-Wars-A-New-Hope.html',
'http://www.imsdb.com/scripts/Star-Wars-Attack-of-the-Clones.html',
'http://www.imsdb.com/scripts/Star-Wars-Return-of-the-Jedi.html',
'http://www.imsdb.com/scripts/Star-Wars-Revenge-of-the-Sith.html',
'http://www.imsdb.com/scripts/Star-Wars-The-Empire-Strikes-Back.html',
'http://www.imsdb.com/scripts/Star-Wars-The-Force-Awakens.html',
'http://www.imsdb.com/scripts/Star-Wars-The-Phantom-Menace.html'
]
def parse(self, response):
"""
Function for parsing response and returning desired text from url page.
"""
for script in response.css('body table td.scrtext'):
yield {
'url': response.url,
'title': ''.join(response.url.split('/')[-1].split('.')[0]).replace('-', ' '),
# '*' will visit all inner tags of p and li (<span><bold> <ul><ol> etc) and get text.
'script': script.css('*::text').extract()
}
Once you have followed the guidelines for setting up a new project and have saved the code above as your spider, from your terminal, navigate to the same directory as your spider project and run:
scrapy crawl scripts -o scripts.json
Where ‘scripts’ is the name of the spider definied in the code above. This will save the text content of each script in a file called ‘scripts.json’.
Preprocess the Data
Now that we have our scripts in a JSON file we can start to prepare them to be modelled as networks. For this part of the post there is also an accompanying Jupyter Notebook.
Visualising the Networks
Gephi and D3 V4.
- How did I get bounding box! - Check out: blah
- How to responsive SVG! - Check out blah
Now that we have our scripts, let’s import it into a Pandas DataFrame and begin to analyse it. For this part, I have also uploaded a Juypter Notebook containing the code which can be found here.
At first glance, the two topics in 2016 look very similar. So to make it a little more obvious and see if there are two distinct topics present, lets just look at the non-overlapping terms:
| 2016 Topic 1 | 2016 Topic 2 |
|---|---|
| Ireland Analytics Companies Research |
Awards DatSci September Event |
From the above table, the two topics that underlie the posts of 2016 become a bit clearer. Topic 1 appears to be concerned with analytics in Ireland in general, and how it is applied by both companies and research. Topic 2 is much more centered on the event of the DatSci Awards itself, taking place in September.
Conclusion
-
The Last Jedi wasn’t released at the time of writing the code for this. However, last I checked (15.03.2018) the script was still not available on IMSDB. ↩
-
All film scripts except Episode 3: Revenge of the Sith conformed to being between
<pre>tags, hence, had to bring it back to the td.scrtext class for code to work for all movies. ↩


Leave a Comment